
이 글은 충남대학교 양희철 교수님의 수업 내용울 바탕으로 작성한 글입니다.
우리가 본격적으로 분류와 회귀에 대해 알아보기 전에 머신러닝이 무엇인지 간략하게 알아보도록 하자
1. 머신러닝이란?
컴퓨터 프로그램이 경험을 통해 과업수행 능력이 상승될 때, 과업의 수행 능력이 경험에 의해 상승하는 것을 말한다. (E : experience, T : task, P : performance)
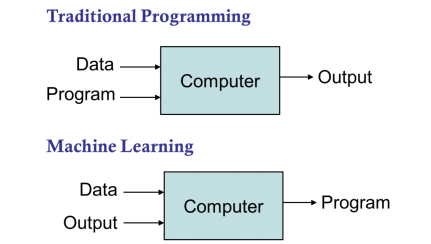

기존의 프로그래밍은 데이터를 프로그래밍해서 결과를 도출했다면 머신러닝은 데이터와 output을 통해 새로운 데이터에 대한 예측을 하는 것이다! 여기서 Input과 output의 관계는 직접 정해주는 것이 아니라, 데이터를 통해서 학습한다. 즉 특정 모사를 하여 관계를 정의한다.
아까 정의를 설명할 때 task, experience, performance라는 단어들이 나왔다. 이들에 대해 알아보자
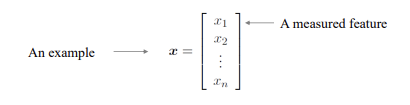
task란 해결해 나가야하는 문제이다! 이 task를 수행하는 능력을 '학습' 이라고 한다. 이 단어는 많이 나올 예정이다. 우리가 이 과업을 수행하려면 두 가지 단계를 거쳐야 한다.
1. feature로 나타내야 한다. 하지만 feature 중에서도 중요도가 낮고, 연산량을 늘리는 feature는 빼야한다.
2. 정량적으로 나타내야 한다. 이 말은 곧 수치적이지 않은, nominal variable은 수치로 변환하여 사용한다는 의미이다.
머신러닝에서의 task 종류에는 무엇이 있을까?
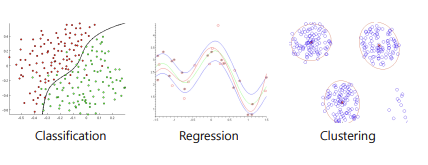
크게 3가지 종류가 있다.
1. Supervised Learning(지도 학습)
- Classification(분류) : Discrete target(categorical value)
- Regression(회귀) : Continuous target
=> x라는 input에 어떤 y값이 나오는가!
2. Unsupervised Learning(비지도 학습)
- Clustering(군집 분포) : 입력 데이터에 대한 분포를 학습한다. 즉 어떻게 잘 그룹핑하는가!
=> input에 대한 관계 만들기(No target)
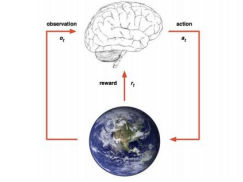
3. Reinforce Learning(강화 학습)
여기서는 크게 다루지 않을 거라 간단하게 말하면 environment와 agent의 상호작용을 agent의 action에 대한 보상함수로 정책을 정한다정도만 알고 있자.
분류와 회귀에 대한 자세한 설명은 나중에 해당 내용이 나올 때 하도록 하겠다~
4. 준지도 학습
일부 데이터만 타겟을 가지고 있을 때, 데이터를 라벨링하는게 시간, 돈, 인력 소모가 되는 현실적 문제를 해결하기 위해서 생기 방법
그 다음 Experience에 대해 알아보자
예시를 들어서 설명하겠다. 사람이라는 데이터셋이 있다고 하자(데이터셋이 바로 experience). 이 데이터셋을 우리는 ID로 나타내야한다(여기서 ID가 바로 data! 사람 이름을 예로 들 수 있다.(홍길동, 김xx...). 그리고 이 각각의 데이터들은 나이, 이름과 같은 feature들로 나타난다(feature가 variable).
이 데이터셋들은 행렬로 나타낼 수 있다. 즉 데이터들을 feature로 표현 시 vector(x=[v1, v2, ..., vn])로 표현할 수 있다. 이때 열벡터로 나타낸다. 이 vector(데이터)들을 합치면 vector space(데이터셋) , 즉 행렬로 나타낼 수 있다.
마지막으로 Performance에 대해 알아보자
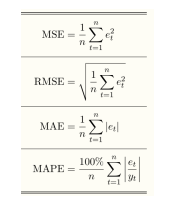
머신러닝의 성능을 정량적(quantitative)으로 측정한다. 어떤 task를 푸느냐에 따라 performance measurement가 달라진다. 위의 예시는 회귀의 성능 측정 도구를 보여준다.
각각의 task에서 어떻게 performance를 측정하는지는 해당 단원에서 설명하겠다. 지금은 이런게 있다는 거 정도만 알아두도록 하자.
# Model capacity(모델의 복잡도)
우리가 학습시킨 모델은 하습 데이터 외에도 새로운 데이터의 문제도 잘 해결해야 한다!
1. Training Performance
트레이닝 데이터에 대해서 학습시킨 성능을 의미한다.
2. Test Performance
새로운 데이터에 대해 모델의 성능을 의미한다. 즉 일반화된 성능이라고 한다.
=> 우리의 목표는 테스트 데이터에 대해 일반화된 성능을 기대하는 것이다. 따라서 테스트 데이터에 대해 적절한 데이터를 뽑아야 한다.
ex) 동양인 데이터에 대해 학습하고 서양인 데이터를 테스트하면 안된다.
기본적인 내용은 이정도만 알아둬도 된다. 다음 시간엔 Bayesian Classifier에 대해 알아보도록 하자.
'AI > MachineLearning' 카테고리의 다른 글
| [ML] Decision Tree (0) | 2024.11.07 |
|---|---|
| [ML] Nearest Neighbor Method (0) | 2024.11.06 |
| [ML] Logistic Regression (0) | 2024.11.06 |
| [ML] Linear Regression (0) | 2024.11.04 |
| [ML] Bayesian Classifier (3) | 2024.11.04 |