
이 수업은 충남대학교 양희철 교수님의 수업내용을 바탕으로 작성한 글입니다
1. Decision Tree

어떤 결정을 내리는데 있어서 트리 구조로 결정을 내리는 것이다. IF-THEN 룰에 따라서 질문을 계속하면서 어떤 경계에 따라 계속 가지를 뻗는다. 쉽게 이해하면 스무고개라고 생각하자!
=> 리프 노드의 어떤 결과가 나오도록 하는 방법을 알고리즘 형태로 정리한 것이 바로 의사 결정 트리이다
Decision Tree의 큰 특징이 무엇일까?

1. Recursive한 partitioning
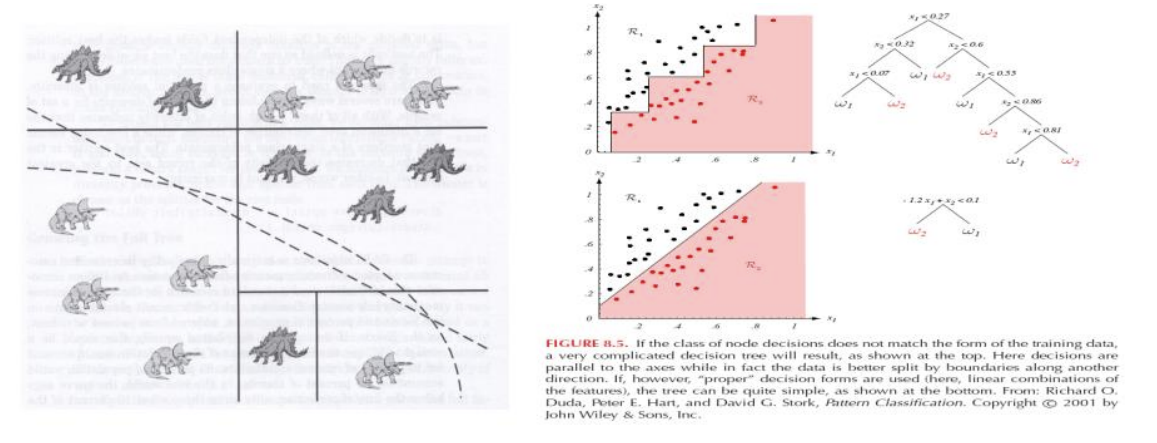
2. 어떤 축에 대해 orthogonal partitioning을 한다.
3. Greedy method : 판단하는 시점에 어떤 경계를 가지는 것이 최적이냐를 판단한다.
=> 모든 case들을 다 고려해서 최적의 경계를 찾는 것이 아니라 지금의 가장 좋은 경계를 만든다.
4. 분류에 대한 명확한 기준이 존재(= model의 해석 가능성이 생긴다)
5. nominal variable, outlier, missing value에 대해 잘 적용한다.
Decision Tree에서 사용하는 용어들을 알아보자

트리에서 사용되는 용어들이 거의 동일하게 사용된다. 한가지 볼 부분은 Split point이다. 어떤 조건에 의해 부모노드가 자식 노드로 나누어지는 부분이다. 그리고 리프 노드에는 최종 분류 결과가 들어있다.
아래에 몇가지 예시를 봐보자.


이 트리를 구성한 것을 feature에 대한 어떤 space로 표현해 봤을 때 축의 orthogonal한 partitioning을 계속 수행한다! 즉 파티셔닝 = 벡터 스페이스 안에서 영역을 나눠줌
Decision tree가 경계를 결정하는 방법에 대해 알아보자


수직적으로 경계를 나누는데 어떤 값을 기준으로 나눌 것이냐가 중요한 포인트이다. 이때 Impurity(불순도)를 사용한다. 불순도라는 것은 경계를 나누고 나서 다른 클래스에 속한 데이터들이 섞여 있는 정도를 나타내기 때문에 불순도가 높다는 것은 분류 성능이 떨어진다.
우리가 불순도를 측정하기 위해 주로 사용하는 것은 Entropy 와 Gini index 이다. 성능을 높이기 위해서는 어떤 variable에 대해서 어떤 split point를 갖고 영역을 나누면 얼마나 불순도를 떨어뜨릴 수 있는가를 구하는 것이 궁극적인 목표이다!
● Entropy : 불확실성을 나타내는 정도
=> 정보가 많다 → 불확실성이 높다 → 엔트로피가 높다
● 어떤 클래스에 속할지가 얼마나 불확실한가
ex)
-3/4log(3/4) + 1/4log(1/4) : 엔트로피
1 - ((3/4)^2 + (1/4)^2) : Gini index
=> 4가지 방법을 살펴보면 확률이 0.5일 때가 가장 불순도가 높다. 이를 통해 4개의 방법의 경향성이 다 비슷하다는 것을 알 수 있다!
불순도가 낮아지는게 좋다고 했다. 그러면 낮아지는지를 어떻게 확인할까?

● InformationGain(S, A) : 전체 data의 엔트로피에서 나눈 부분의 엔트로피들의 합에 가중평균을 곱한 값을 빼서 구할 수있다.
● Impurity drop : 전체 불순도에서 나눈 부분들의 불순도를 더해서 빼서 구한다.
예시를 보면 더 이해가 쉬울 것이다.


아까 주로 사용한다했던 지니 인덱스와 엔트로피는 결과값의 차이가 많이 날까?

확실히 결과 값의 차이가 있는 것을 알 수있다. 하지만 어떤 방법을 쓰던 간에 정답이 있는 것은 아니다.
Decision Tree는 그리디 알고리즘을 따른다고 했다. 따라서 실행할 때마다 결과가 다르다. 이에 대해 조금 더 알아보자

현재 자신의 상황에서 최적의 선택을 하기 때문에 Local Optimum이다. 즉 현재 상황이 전체적으로 뵜을 때는 최적이 아닐 수 있다는 것이다.
파티셔닝을 통해 트리를 만드는데 언제 멈춰야할까?
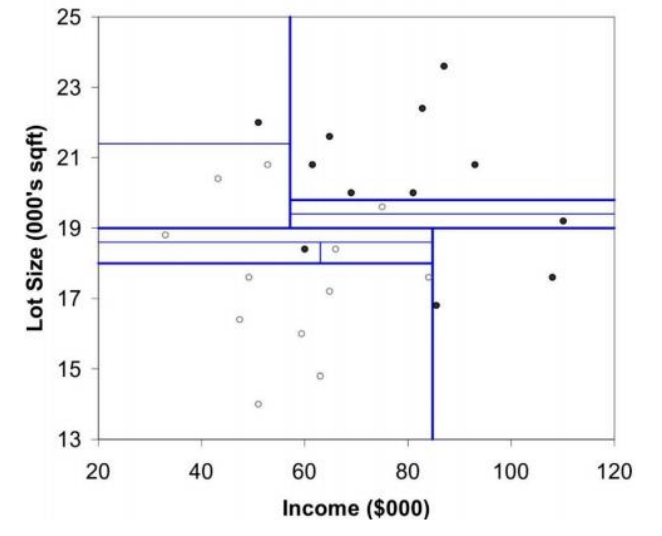
우리가 머신러닝에서 가장 경계해야하는 것이 오버피팅이라고 생각한다. Tree가 커질수록 모델의 capacity는 커지지만 test performance가 감소할 수 있고 너무 tree가 작으면 언더피팅될 수 있다. 따라서 잘 멈추는 것이 중요하다.

첫번째 방법은 훈련 데이터, 테스트 데이터로만 쪼개는 것이 아니라 validation data를 사용하여 중간중간에 검증할 수 있다. 보통 70%를 훈련데이터, 30%를 검증데이터로 사용한다. 이 방법은 데이터의 양이 많지 않다면 사용하기 힘들다.
결국 우리는 인위적으로 멈추게 하던가, 규제를 적용해주어야 한다.

1. 인위적으로 지정
● 최대 depth, 최대 리프노드 수, 스플릿을 위해 필요한 최소한의 데이터 개수 => 한계가 존재
2. 규제 적용
● 트리 사이즈에 대한 반영을 얼마나 할 것인가
Decision Tree에서의 규제 방법을 알아보자

프루닝, 가지치기라고 한다. 학습 이후에 불필요한 가지를 잘라내는 것을 말한다. 쳐내는 가지의 기준은 impurity drop이 가장 낮은 부분이다. 이 방법은 validation data도 필요없으나 잘라내기 위한 연산에 대한 부담이 존재한다.

pruning 이후에 cost가 증가하지 않는다면 해당 가지를 잘라낸다. a가 크다는 것은 프루닝을 더 하겠다는 의미, 더 규제하겠다는 것이다.
=> Tree 사이즈를 작게 했을 때 이득이 더 크면 프루닝을 진행한다.
남아 있는 Decision Tree의 장점에 대해서도 알아보자


스플릿 포인트를 nominal variable을 기준으로 할 수 있고, outlier 및 Missing value를 잘 처리할 수 있다는 장점이 있다. Missing value의 경우 데이터를 안쓰거나 다른 값들을 보고 평균값으로 놓거나 스플릿 포인트로 쓸 수 있다.
추가로 명시적인 결과를 나타내서 피처에 대한 중요도를 파악할 수 있다. 비선형한 경계도 가능해서 성능을 높일 수 있다. 그러나 명시적인 의미는 나타낼 수 없다.
Decision Tree는 주로 분류 문제에 사용하지만 회귀 문제에도 사용가능하다
정리하자면...
● 쉽게 사용, 이해할 수 있다.
● 명시적으로 쉽게 해석할 수 있는 결과를 만든다.
● 다른 모델에서 다루기 힘들어한 값들을 잘 다룰 수 있다.(outlier, nominal variable, Missing value)
● 프푸닝으로 규제 가능하다.
● 그리디하고 수직적으로 파티셔닝해서 성능이 낮다.
다음 시간엔 이 트리를 사용한 앙상블에 대해 알아보자
'AI > MachineLearning' 카테고리의 다른 글
| [ML] Neural Networks (3) | 2024.12.07 |
|---|---|
| [ML] Ensemble method (0) | 2024.12.07 |
| [ML] Nearest Neighbor Method (0) | 2024.11.06 |
| [ML] Logistic Regression (0) | 2024.11.06 |
| [ML] Linear Regression (0) | 2024.11.04 |