
이 글은 충남대학교 양희철 교수님의 수업을 바탕으로 작성한 글입니다
1. Neural Network
신경망 구조로 뉴런들을 많이 연결시켜서 신호를 전달한다. 신경의 전달 과정을 수학적으로 모방(신경에 전달되는 값이 변화를 일으키며, 즉 weight가 곱해져서 전달하는 머신러닝 모델의 가장 일반적 형태이다
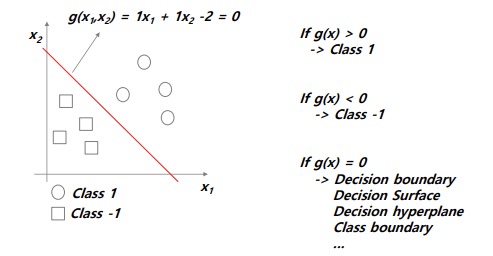

x1, x2에 적절한 weight가 곱해진 값을 다 더하면 0보다 크냐, 작냐를 물어보고 0(decision boundary)보다 크면 1, 작으면 -1이다의 함수로 모델링한다. 이러한 구조는 가장 linear한 경계를 가지는 분류 모델이다
좀 더 일반화해서 나타내보자


i개의 feature가 있고 각각에 대해서 가중치를 곱해주고 bias가 더해진다. 이를 가중합이라고 한다. 이 가중합을 함수를 통과시켜서 나온 값을 출력으로 가진다. Input이 data, 나머지 부분이 모델에 대한 출력이고 g(x)는 W벡터와 x벡터의 내적으로 나타낼 수 있다.
=> g(x) = WTX, y = f(g(x))
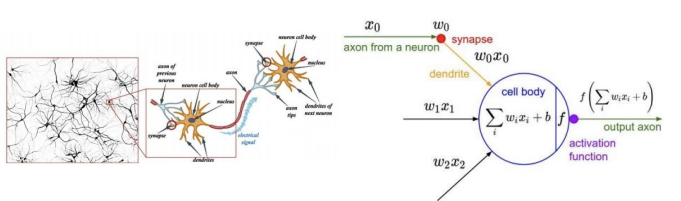

입력 값을 다음 뉴런에 전달해줄 때의 모델링이다. 입력 값에 각 weight를 곱하고 bias와 더하여 나온 값을 특정 함수에 넣어서 output을 도출한다. 이런 구조를 퍼셉트론이라고 한다! 단일 퍼셉트론은 활성화 함수로 step function을 사용한다(미분 불가능)
구조를 보다 보니 함수가 하나 있다. 이를 우리는 activation function이라고 한다

어떠한 형태를 가져야 하는지 정해진 것은 없으나 후보군은 있다. 뉴런의 자극 세기를 바꿔가면서 어떻게 출력되는지를 보는 것과 같다.
=> 입출력 관계과 logistic과 유사한 형태를 가지더라는 식으로 판단한다
Q. 활성화 함수를 왜 써야하나요? 이에 대한 예시를 보면서 MLP에 대해서도 알아보자
ex1) 선형적 관계

=> 큰 문제 없이 선형적으로 잘 해결하였다
ex2) 비선형적인 관계(XOR)

=> 단일 퍼셉트론으로는 nonlinear한 문제를 풀 수 없다. 이를 풀려면 직선을 두 개 그리거나 곡선을 하나 그려야한다
※ 다중 퍼셉트론

=> 다중 퍼셉트론을 활용하여 nonlinear 문제를 해결할 수 있다. 단일 퍼셉트론의 input layer, output layer 사이에 hidden layer를 추가한 구조이다. 이때 activation function으로 nonlinear한 애들을 사용해주어야 한다


=> nonlinear한 활성화 함수를 사용하기 때문에 nonlinear problem을 해결할 수 있다!
nonlinear한 문제를 해결하기 위해 MLP를 사용한다는 것까지 알게되었다. MLP는 단일 퍼셉트론과 달리 hidden layer를 가지고 hidden layer에서의 노드 수가 충분하다면 어떠한 nonlinear한 경계로 표현해줄 수 있다. 이를 우리는 Universial approximation theory라 한다
2. Feedforward vs Backpropagation

Input layer의 노드를 히든 레이어의 여러 노드에 다 통과시키고 그 결과를 최종 출력을 내는 노드에 입력으로 넣어줌으로써 최종 출력을 내게 된다.
● 역전파 : 모델이 적합한 입출력을 가지도록 학습한다
● 순전파 : Input을 넣어 결과를 내는 과정이다.
먼저 순전파부터 보도록 하자


y는 가중합을 활성화 함수에 통과시킨 값이고 output을 loss function에 사용해 loss를 구한다



Output Layer에서 활성화 함수는 출력을 내기 전 단계이므로 모델이 풀고자하는 task, 원하는 출력 형태와 크기에 맞춰 사용한다
ex) 분류 문제에서 이진 분류라면 1개가 필요, 다중 분류라면 클래스의 개수만큼 아웃풋 노드가 필요하다.
회귀 문제라면 예측해야하는 값의 수와 같다(집의 크기과 값을 예측해야한다면 2개)
※ 주의 : hidden layer 개수를 늘리면 늘릴수록 복잡한 모델이 되므로 overfitting을 조심해야 한다!

Regression 문제에서는 활성화 함수를 안써도 된다. 예를 들어 회귀 문제인데 sigmoid를 활성화 함수를 쓴다는 것은 문제가 있다. 따라서 출력 형태에만 문제 없으면 된다
순전파의 마지막 과정인 loss function에 대해 알아보자

Loss가 있다는 것은 모델을 학습해줘야한다는 의미이다. 우리가 모델에서 학습하는 대상은 가중치라는 걸 기억하자. 따라서 output을 통해 weight 값을 조정해서 최적의 값을 찾는다. output이 있을 것이고 원하는 target output이 있을텐데 이 둘의 차이를 가지고 이 모델이 어느 방향으로 얼마만큼 업데이트 되어야하는지, 이를 Loss function으로 둘 수 있다
그렇다면 우리가 loss를 어떻게 줄일 수 있을까?
Backpropagation을 사용한다!
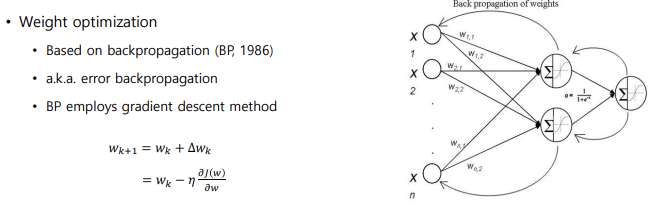
역전파, 즉 모델의 학습 = weight의 학습이다. Loss로부터 weight들을 차례차례 업데이트해 나가는 것이다. 사용하는 optimizer는 경사하강법, 방향은 정하되 얼마나 가야할 지 알 수 없다. 따라서 적절한 학습률을 곱해서 곱한 만큼 update해야한다.
Q. 왜 역전파인가요?

A. 예측값과 타깃값을 통해 loss를 계산하고 이 loss를 가지고 다시 weight를 업데이트해주기 위해서 loss를 원하는 weight에 대해서 편미분한 다음에 학습률을 곱해서 빼준다. 계산이 어렵기에 weight가 loss에 미친 영향을 끝에서부터 차례차례 계산하는게 역전파이다. 이때 역전파 계산 시 편미분을 진행하는데 연쇄법칙을 이용한다
예시를 보는 것이 더 이해하기 쉬우므로 예시를 보도록 하자

=> 우리가 알고 있는 값들은 이전 노드에서 구한 가중합을 활성화 함수를 통과시킨 값과 이 값들의 가중합들이므로 이들을 연쇄 법칙으로 나타낸다. 알고 있는 값들을 가지고 미분한다

직접 계산한 것을 보고 싶다면 아래의 링크를 참고하길 바란다!
https://luckychaser.tistory.com/18
[DL] 딥러닝의 구조
이전 시간에 머신러닝 때 학습했던 내용 중 중요한 내용들에 대해서 정리해보았다. 오늘부터는 본격적으로 딥러닝에 대해서 학습해보도록 하자 1. 딥러닝이란? 인간의 두뇌에서 영감을 얻
luckychaser.tistory.com
Neural Network에 대해 정리해보자면...

weight 업데이트를 뒤부터 차근차근 하나씩 update하여 적절한 횟수 제한이 있을 때까지 반복해서 업데이트한다. 새로운 데이터에 대해서는 feed forward만 하면 된다. 학습과정에서는 데이터를 입력으로 넣어서 feed forward하고 출력에 대한 학습 이후 Backpropagation으로 loss를 줄인다
추가적으로 두가지만 더 알아보도록 하자

학습률은 하이퍼파라미터, 적절히 잘 가지는 것이 중요하다. 학습률이 너무 크면 방향은 맞는데 발산하는 경우도 있고 너무 작으면 수렴하는데 너무 많은 시간이 걸리거나 도달하지 못할 수 있다
Local optima 문제가 존재한다

데이터를 랜덤으로 정하기 때문에 Global minimum이 아닌 local minimum에 도달할 수 있다. 하지만 이는 이론적으로 풀 수 없어 해결 방법이 없다. 즉 함수가 convex(볼록함수) 형태가 아닐 때 어떻게 최적값에 도달하느냐에 대한 방법은 불가능하다.
=> local optimum에 도달해도 이론적으로 어느정도 충분한 성능을 낼 수 있다!
다음 시간엔 DNN에 대해 알아보겠다
'AI > MachineLearning' 카테고리의 다른 글
| [ML] Deep Neural Networks (0) | 2024.12.07 |
|---|---|
| [ML] Ensemble method (0) | 2024.12.07 |
| [ML] Decision Tree (0) | 2024.11.07 |
| [ML] Nearest Neighbor Method (0) | 2024.11.06 |
| [ML] Logistic Regression (0) | 2024.11.06 |