
이 수업은 충남대학교 양희철 교수님의 수업을 듣고 작성한 글입니다
1. K-nearest neighbor classifier (k - NN)

가장 직관적이고 쉬운 분류 알고리즘이다. K개의 근접한 이웃 데이터를 보고, 새로운 데이터의 분류를 판단한다. 즉, 가장 비슷한 애들이 나를 설명한다! 주변 데이터와의 거리를 측정하여 이를 기반해서 분류하므로 데이터를 직관적으로 활용 가능하다.
k-NN을 관통하는 가장 중요한 단어는 바로 '거리'이다
# Distance

feature의 개수는 차원을 의미하고 가장 근접한 k개의 데이터를 보고 판단한다. 우리가 거리를 구하기 위해서는 data를 벡터 스페이스에 표현해야한다!
거리는 어떻게 구할 수 있을까?
# Manhatten distance

D(x,y)는 feature를 가진 데이터 포인트를 나타내고 L1-norm을 이용하여 차의 절댓값을 취해서 더한다. 이 거리는 grid 상의 거리와 같다.
# Euclidean distance

우리가 일반적으로 쓰는 방법이다. L2 놈을 이용해서 제곱에 절댓값을 이용한다. 이 식은 2차원에서만 사용되는 것은 아니다. 이 거리는 직선 거리와 같다.
# Mahalanobis distance

왜 분산을 나눠서 보정을 할까? 거리가 상대적이기 때문이다. 예를 들어보자.
ex) 내가 국어를 잘 본 학생, 못 본 학생이 0점, 100점이 많을 때의 5점 차이와 수학은 다들 잘 봐서 80점 ~ 100점에 몰린 경우 5점 차이가 나는 것 중 뭐가 더 클까?
=> 당연히 후자가 더 크다.
따라서 feature 각각의 독립적이라면 covariance로 나누어 표준편차로 나누고 제곱한 효과를 주고 이를 통해 분산에 대한 보정을 해준다!
nominal한 경우, ordinal한 경우는 어떻게 거리를 계산할까?
# Distance metric


Ordinal variable은 불연속적 값이지만 순서가 존재하는 걸 말한다. 예를 들면 별점, 평점 같은거! Nominal variable은 카테고리에 대해 0 또는 1로 라벨링 해준다.
=> 깂의 차이가 어떤 의미를 가지느냐 or 거리의 차이가 존재해야 하는가!
그런데 거리가 잘 측정되려면 값들의 기준이나 범위가 같아야하지 않을까?
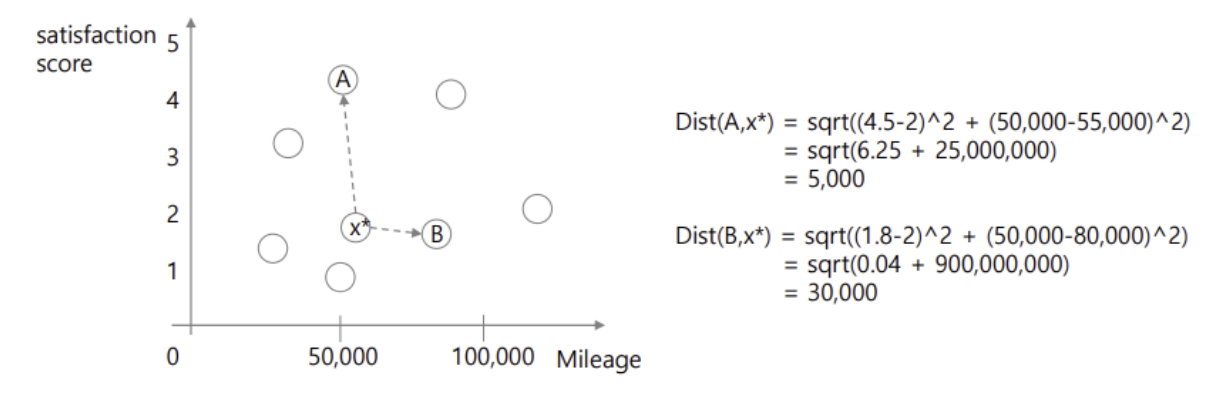
이 사진을 보면 분명 A와 더 멀리 떨어져 있는데 B와의 거리가 더 멀다. 그 이유는 x축의 범위는 0 ~ 100,000 이고 y축의 범위는 0 ~ 5 이다. 따라서 x축으로 늘어날 때와 y축으로 늘어날 때 영향이 다르다!
2. Normalization


거리를 계산하기 전에 각각의 feature에 대한 scale의 차이를 먼저 보정해주는 사전처리 방법이다. 두 가지 방법이 있다.
1. z - normalization : 표준정규 분포로 옮겨줌(각 feature 별로 평균과 표준편차를 구함)
2. Min - max normalization(scaling)
=> 우리는 2번 방법에 대해 예시를 보자


다시 돌아와서 k-NN 알고리즘의 특징에 대해 알아보자
● 진행과정
1. 클래스에 대한 라벨과 피처들에 대한 normalization을 한 후에 값을 정리한다.(reference vector)
2. 새 데이터가 들어오면 클래스 라벨이 없는 분류 문제를 해결해야 한다.
3. 기존 데이터와 새 데이터 사이의 거리를 계산한다.
4. 거리가 가장 가까운 k개 선택한다
● K 값에 따른 차이점
K 값에 따라 결과가 달라진다. 따라서 k를 어떤 값으로 정의하느냐는 중요한 요소이다!
k를 정하는데 정답은 없지만 k값이 클 때와 작을 때의 차이점을 보자

● k가 클 때
1. k를 크게 잡으면 클래스를 선택하는 경계가 smoothing!
2. 결과가 확 바뀌지 않음
=> sensitive하지 않아서 언더피팅 되는 경향이 있다
3. 일반화 측면에서 장점 존재
● k가 작을 때
1. k가 작으면 굉장히 빠르게 변한다. 주변의 1, 2개에 의해 확 바뀐다
=> sensitive해서 오버피팅되는 경향이 있다.
2. 복잡한 모델을 갖는다.
그러면 적절한 k값은 어떻게 찾아야할까?

시행착오를 겪어서 찾아야 한다! (trial and error) 그리고 홀수 값을 해야 분류가 잘 된다.
k-NN은 단순하다는 장점이 있지만 치명적인 단점이 있다...!
바로 Lazy learner 라는 치명적인 단점이 있다. 즉, 미리 학습(사전 학습)을 해서 새 데이터에 대한 결과를 내는 것이 아니라, 새 데이터가 들어오면 그것과 기존 데이터와의 거리를 계산하는 방식이다! 실제로 모든 거리를 다 계산해보고 기존 데이터를 계속 가지고 있어야하기 때문에 메모리, 시간 효율이 매우 떨어진다.
그렇지만 매우 단순하고 비선형이라는 장점이 있어서 사용한다!
다음 시간엔 decision tree(의사결정트리)에 대해 알아보자!
'AI > MachineLearning' 카테고리의 다른 글
| [ML] Ensemble method (0) | 2024.12.07 |
|---|---|
| [ML] Decision Tree (0) | 2024.11.07 |
| [ML] Logistic Regression (0) | 2024.11.06 |
| [ML] Linear Regression (0) | 2024.11.04 |
| [ML] Bayesian Classifier (3) | 2024.11.04 |